
How to use Elasticsearch to Create an Exceptional User Experience in Retail
Search, and ye shall find
aging tutorial
- 🗓️ Date:
- 🗓️ Last modified:
- ⏱️ Time to read:
Table of Contents
You just went to the Google home page. What do you see?

A search box, inviting you to type something. Well I’m a programmer, so I’ll just go ahead and type in the word recursion.
Haha. A recursion joke. You’re funny, Google. But jokes aside, let’s look at the top 5 results:
It probably took less than a second for Google to return me documents from the web that are about recursion. All ordered neatly in order of their relevance.
If you’re reading this on your phone or laptop right now, you’ve likely heard of the term Search Engine. A search engine is a software component that allows you to find information in a computer. It usually consists of an interface that lets you enter a search query - where you specify criteria about an item of interest. This could be in the form of words relevant to the specific topic (such as COVID-19, or The Matrix), and the search engine uses these words to find the relevant information from a database. The search results are usually presented in a list and are commonly called hits, which are displayed to the user.
Often referred to as a Web Search engine, Google took “Seek, and you shall find” to a whole new level. But that’s not the only place where they’re used. Any domain or industry that relies on the power of computing can benefit immensely from a search engine. In particular, the ability to find documents or information within a system is critical to creating a great user experience for users. Hence, search engines are used in many customer-facing applications across web, desktop and mobile devices.
For instance, in e-commerce platforms such as Amazon, search is used to find products across multiple categories such as clothing, electronics and furniture. Search is also used in blogs and news publication platforms to find articles or sources of information for research. And in entertainment platforms like Netflix, search allows you to find content that you like from a massive catalogue of movies, TV shows and music.
Let’s look at a popular open-source software that powers the search feature for some of the world’s most widely used enterprise software.
Elasticsearch
Elasticsearch is a free and open-source search engine allowing you to search for nearly any kind of information - including textual, numerical and geospatial data. It emerged from an earlier open source project called Lucene, primarily to provide the following features:
- Handle terabytes of data.
- Do large scale parallel searching really fast.
- Use inexpensive commodity hardware to scale and increase search speed.
In order to achieve the above, what started out as a search box within applications has become a NoSQL database in its own right. Elasticsearch is popularly used along with the ELK Stack, or simply the Elastic Stack. It is a collection of products offered by the Elastic company, and consists of the following components:
- Elasticsearch, which powers the other components as a distributed JSON-based search engine.
- Logstash: As Elasticsearch started to see widespread usage, users wanted a way to search for logs and compile data for analysis. Logstash is an open server-side data processing pipeline engine which helps with a variety of data analysis and transformation related tasks.
- Kibana: A visual user-interface that provides an admin dashboard and data visualization tool for managing and debugging data within Elasticsearch. Users can use Kibana to create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
Some of the most popular use-cases built using the Elastic Stack are:
- Powering complicated search feature within applications which involve sophisticated querying and filtering.
- Telemetry, logging and metrics.
- Business Analytics.
- Forecasting and anomaly detection.
Here’s an excellent visual story on how search can be leveraged in a myraid of ways.
Let’s examine how the Elastic Stack can be used in more detail by considering a use-case.
Search in Retail
In retail platforms, search is a powerful and an integral part of the shopping experience. Here are some interesting statistics:
Search Statistics
- A recent report from Forrester indicates that over 43% of users on retail websites go directly to the search bar to shop for products.
- Screen Pages analyzed search usage across 21 e-commerce websites and found that the average revenue from visitors using search were significantly higher than those by non-search users.
- More than half of all internet traffic comes from native mobile applications, meaning the search experience plays a crucial role in helping users find what they’re looking for without exiting the application. This is especially the case when mobile users spend nearly 20x more time shopping than website users!
Elasticstack in Retail
If you’re reading this, you’re probably wondering whether your app or business can benefit from Elasticsearch. The Elastic Stack is used by some of the world’s top e-commerce and retail business in-order to enhance the shopping experience for customers. Here are a few examples:
Ebay leverages Elasticsearch to help users find relevant products over 800 million records.
But this isn’t necessarily limited to only shopping. Shopify uses Elasticsearch to add a powerful search feature for the documentation part of their website!
You can find several more usecases on retail here.
At Egen, we work with some of the world’s largest retail brands in-order to modernize their IT architecture and help scale. We’ve put together a short tutorial to demonstrate and help you understand how you can use the ELK stack for your own retail business or application.
Let’s first explore what a search experience looks like in online shopping.
Search Experience in online shopping
Here’s how a typical search looks like on Amazon or any other online shopping platform. There are generally 3 main categories of search:
Text Search
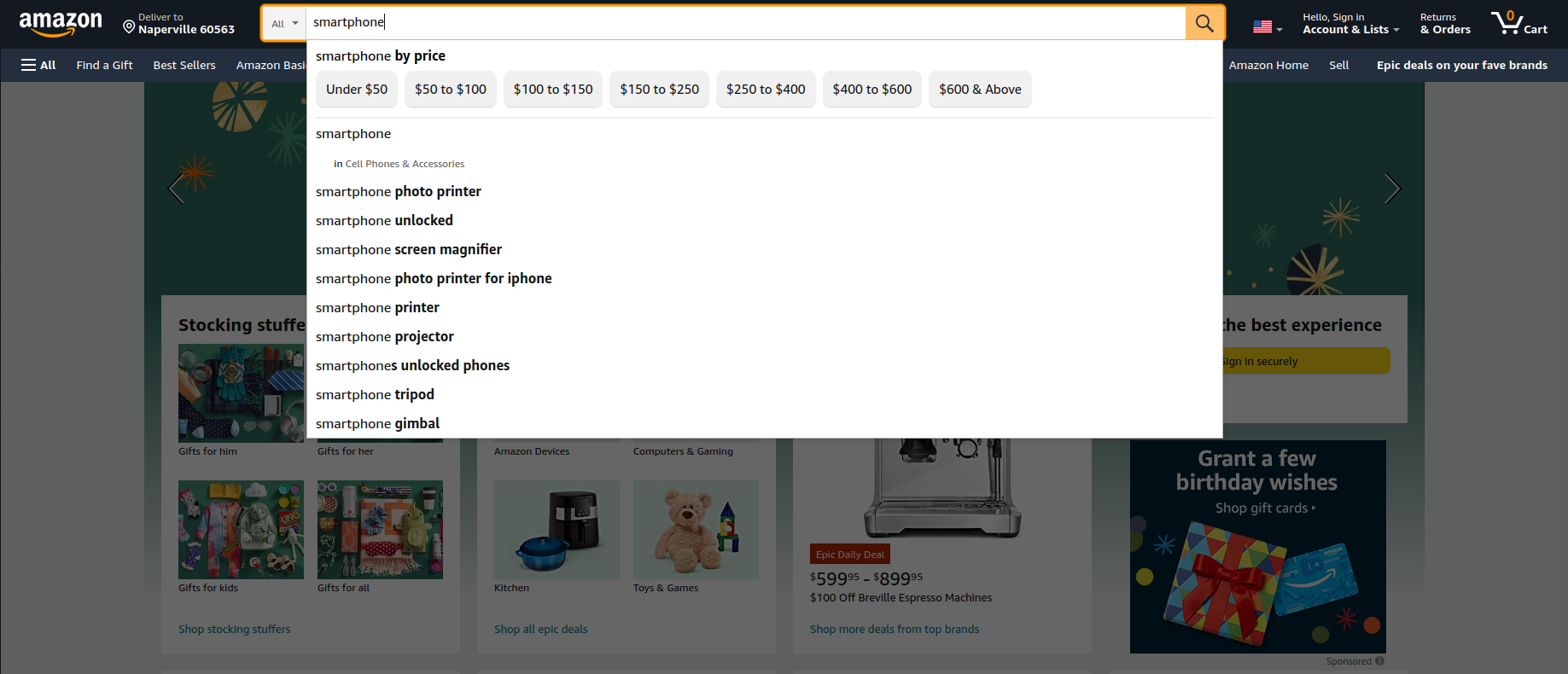
The home page of Amazon shows a search input box. If I want to check out smartphones, I could simply enter “smartphone” in the search box.
This search functionality allows a search across multiple departments or categories.
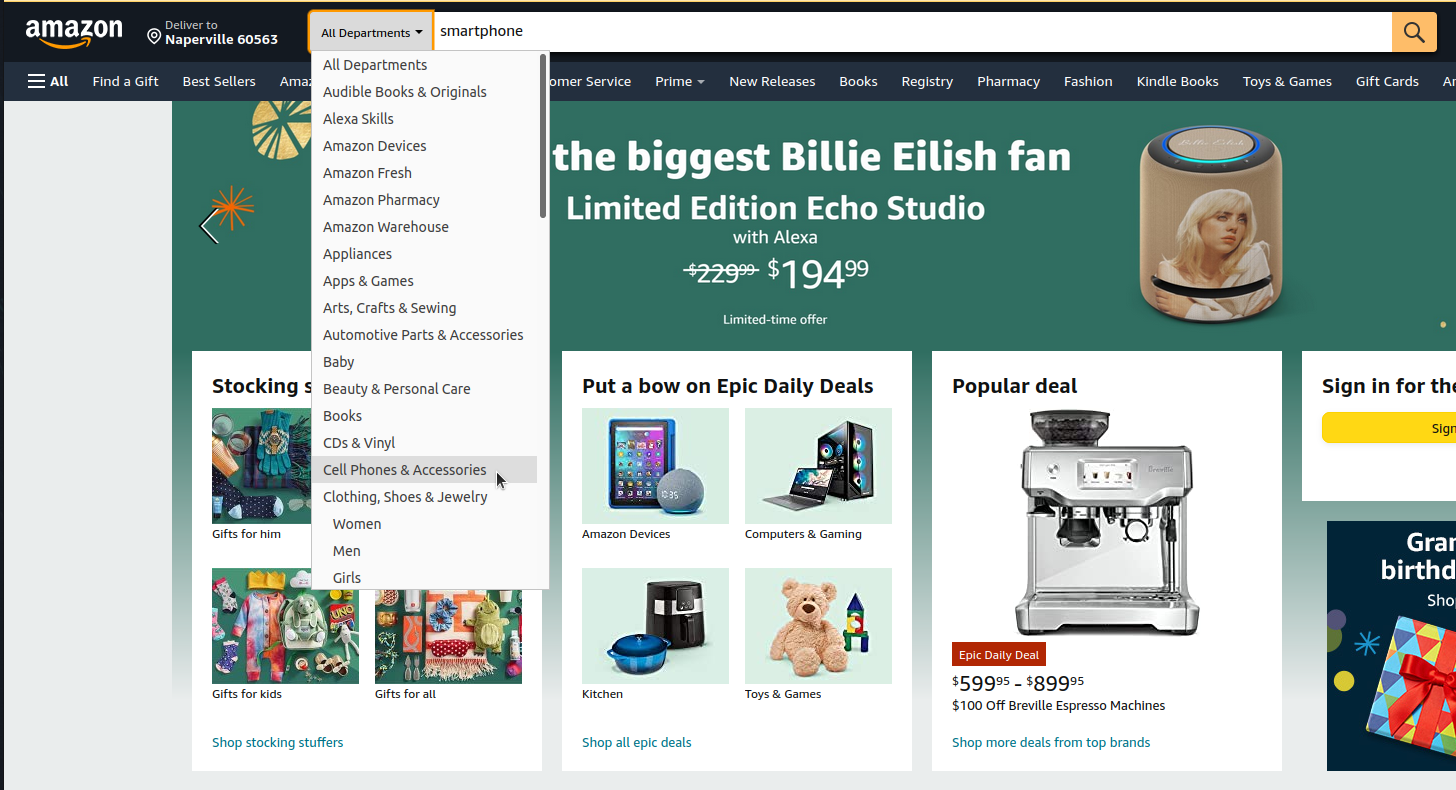
Search within departments or categories
Alternatively, users can also search for products within a certain department.
Filtering
Users also have the option to apply a variety of filters to include and exclude products based on multiple criteria.
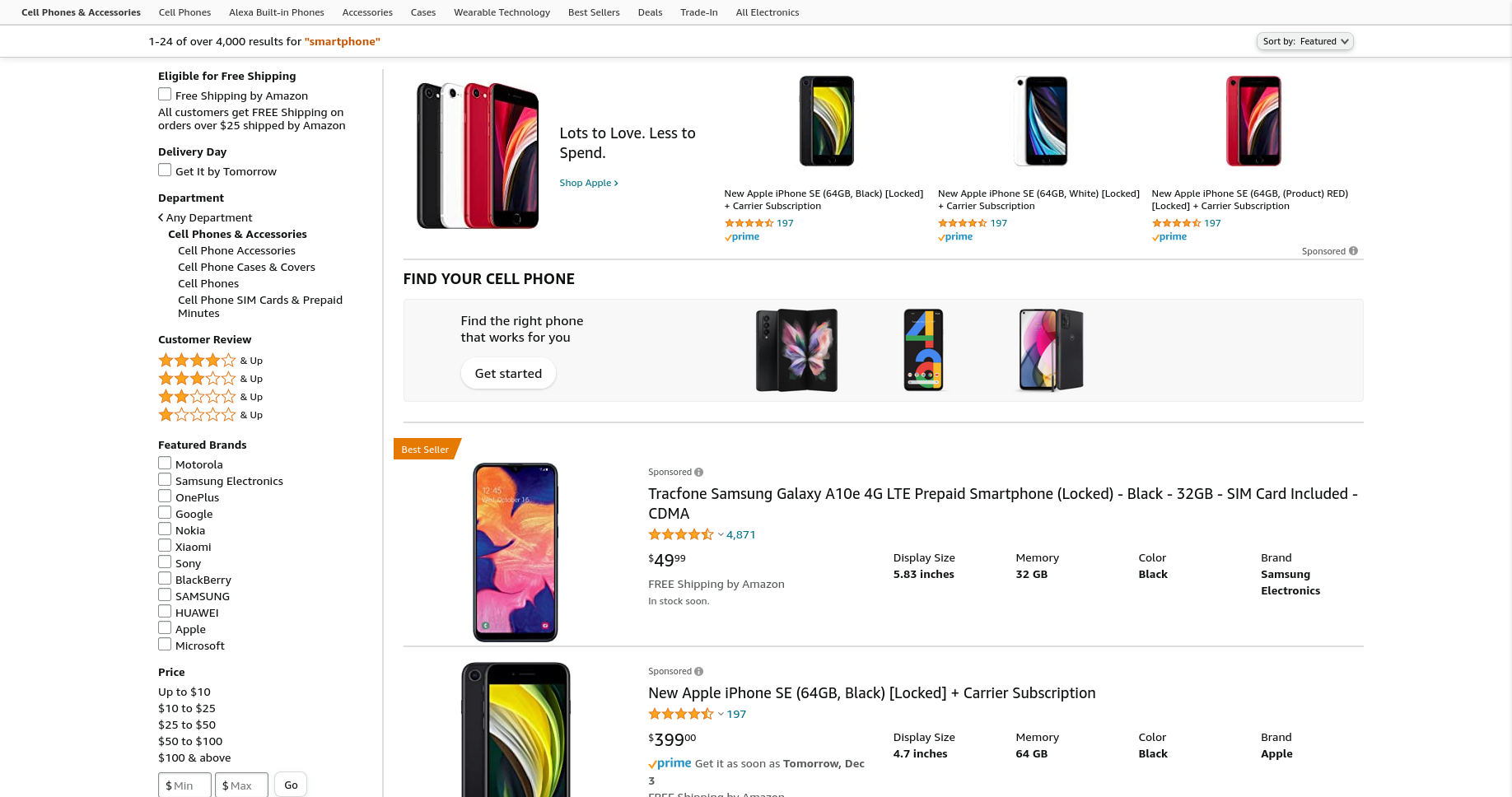
Here are some common filter types:
- Yes/no or boolean type filters. For example, fetch products which have single day deliveries.
- Multi select filters which include products belonging to certain brands.
- Range filters which include searching for products within a certain price range, or above a certain customer rating score.
Sort search results
Users can also decide how they’d like the search results to be sorted, based on factors such as pricing or average reviews:
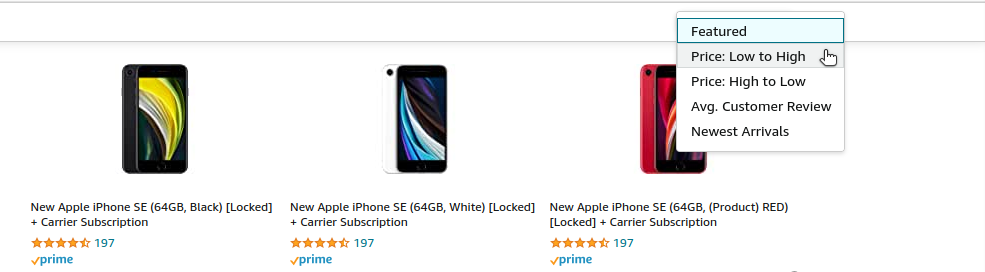
Let’s look at how Elasticsearch can help you provide similar such search experience for your retail application.
What you will learn
Demo
Here’s a demo e-commerce website with search and filtering powered by Elasticsearch:
You’ll learn the features of Elasticsearch used to create the above website and similar such search experiences!
For the purposes of this tutorial, I will be using a dataset from Kaggle, that contains pre-crawled information of products from Flipkart, a leading Indian eCommerce platform similar to Amazon. You’ll learn how to leverage Elasticsearch’s powerful APIs in online shopping to search for relevant products that you can purchase from an e-commerce platform.
In-order to use the Elastic Stack, you have the following options:
- Install Elasticsearch, LogStash and Kibana on your own hardware or cloud service provider.
- Use the managed Elasticsearch cloud offering from the company Elastic.
Once you’ve installed, open up the Kibana console, and import your dataset:
Data Exploration
When you begin the process of uploading your data, Kibana scans through the first 1000 columns or documents and returns a summary of the file contents in the visual data explorer.
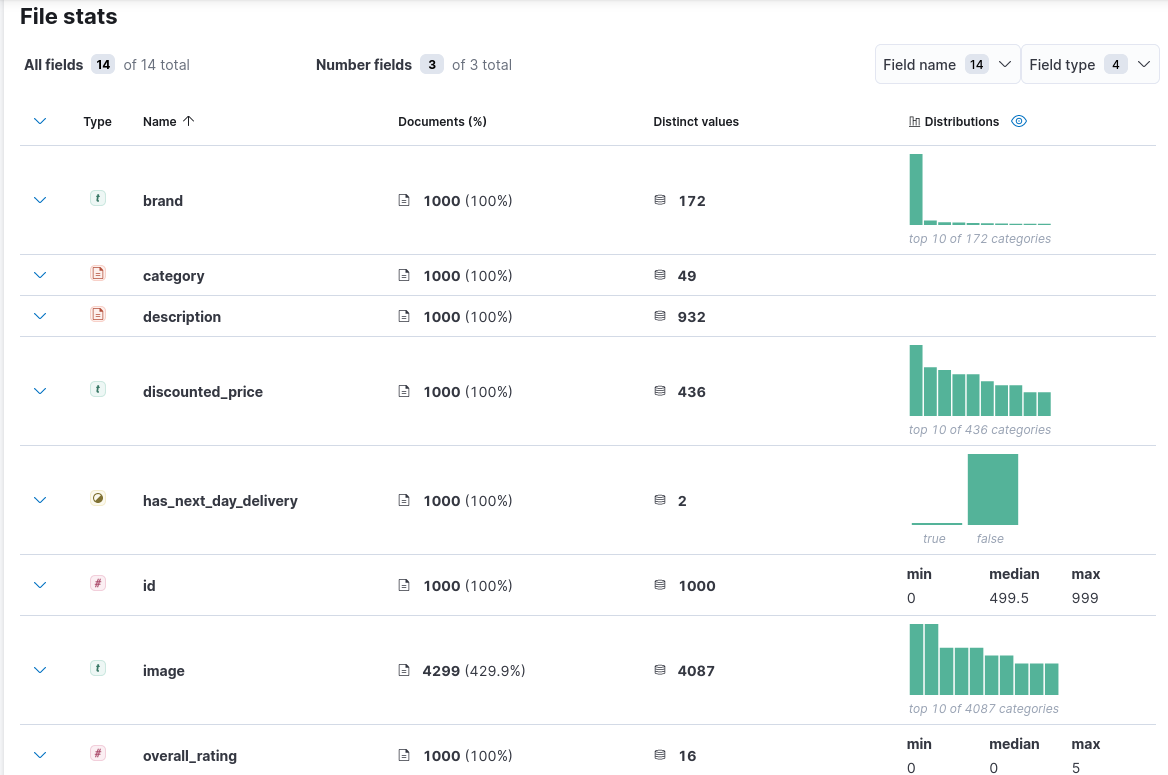
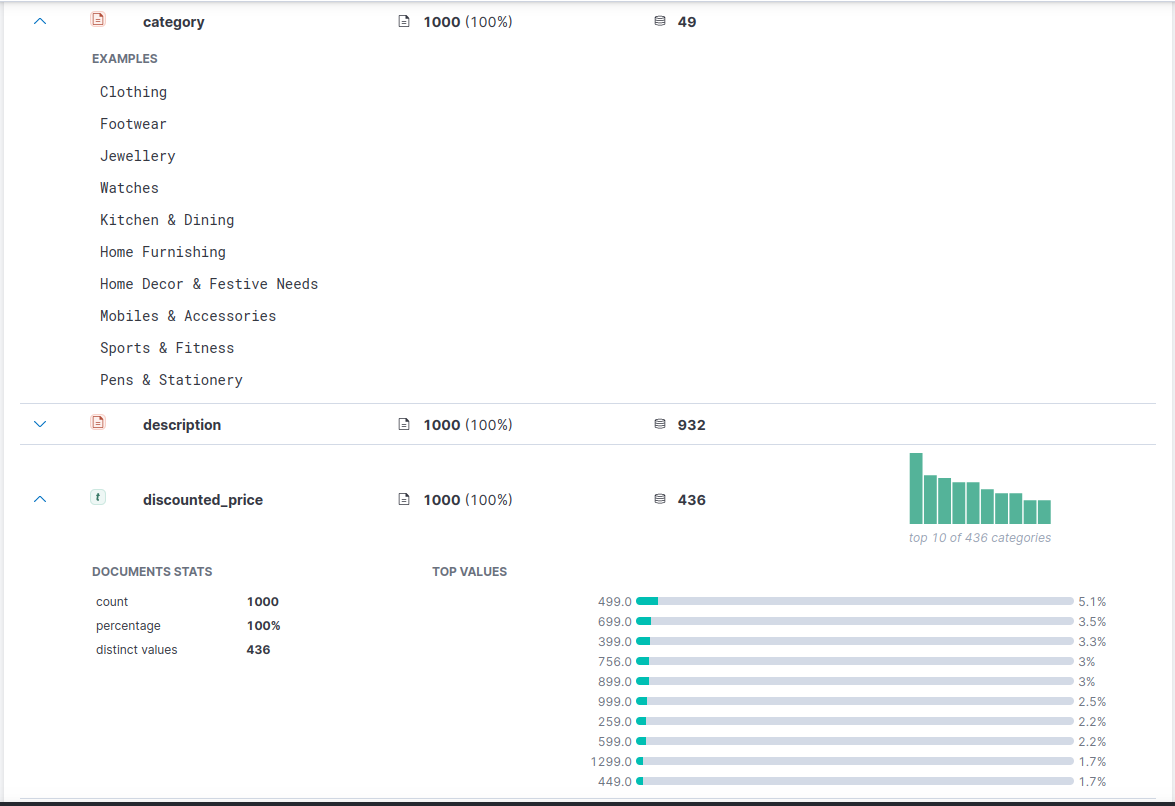
The explorer shows you the fields in your dataset, the number of distinct values in them, along with the distribution of those values.
As you proceed with importing your data, Kibana will ask you to create an index.
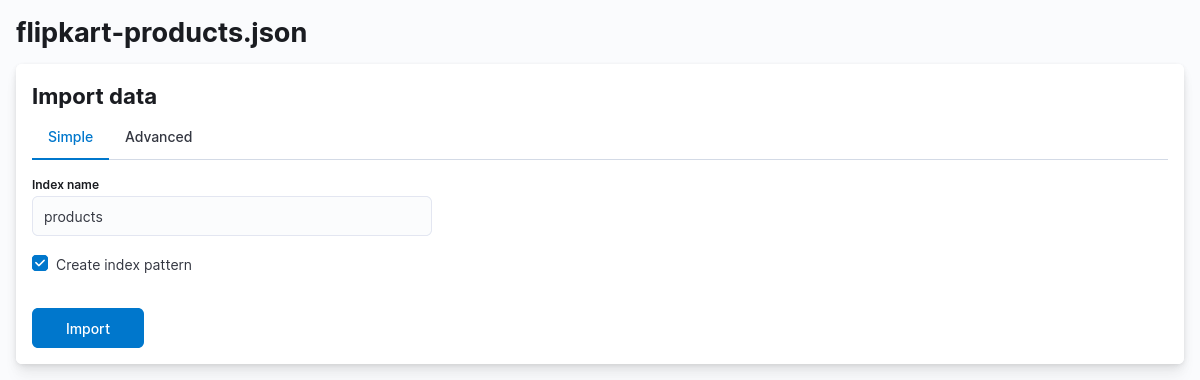
If you go with the simple import, Kibana automatically assigns a default data-type to the individual fields in your dataset.
But I personally find the advanced import to be more useful, as it allows me to view and choose the most appropriate data-type for the fields in my data.
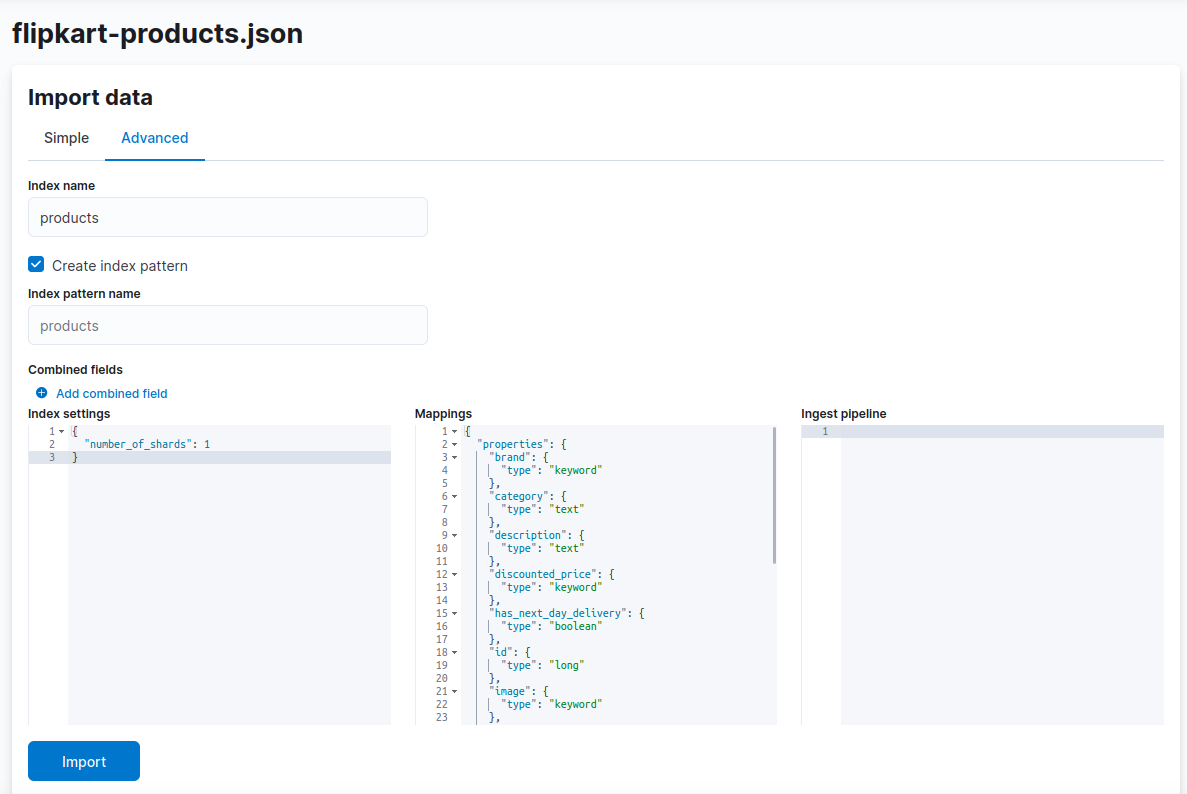
Data types and field mappings
Elasticsearch provides common data-types like text, boolean, keyword and numbers, and also some advanced data types like object, range, date and geo-spatial. Here’s the complete list.
In the advanced import section, you’ll be able to review the data-type mappings for the fields/columns in your dataset and modify them if necessary.
Here are the types Kibana assigned to my dataset fields by default:

To understand what data-type fits best, let’s study our fields in more detail:
product_name
The name of the product. This is of the text type.
description
As the name implies, this contains the description of a product. This too, is of the text type.
category
The department or category that a product belongs to. When I uploaded my dataset into Kibana first and checked the mappings, I found that Kibana had assigned it a text type. But it is better to assign it as a keyword type instead.
Why is this important?
Elasticsearch optimizes certain fields to perform well for certain kinds of queries.
In our dataset, the category field is useful when its made into a keyword rather than ordinary text. The reason being - shoppers often look for products within a certain category, and these categories always contain the same value.

Keyword types are also useful in aggregation queries - for instance, how many products are in each product category?
brand
The brand name of the product. By default, this was assigned a keyword type.
In e-commerce platforms, shoppers often use filters while searching for a product across different brands - for example, Adidas. In which case, a keyword type fits well.
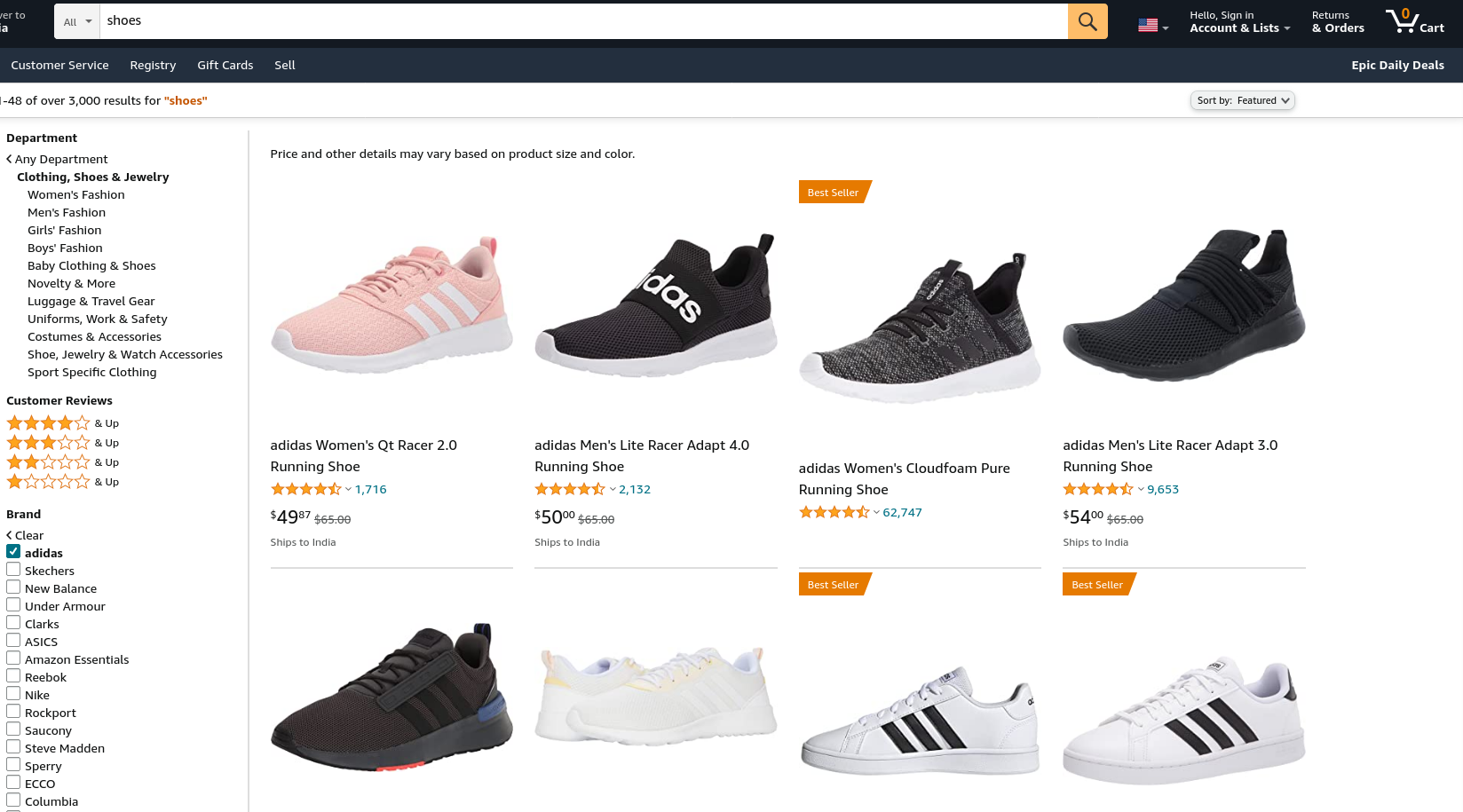
On the other hand, shoppers also often search for specific brands by directly entering the brand name on the search bar, like “Adidas shoes”. In which case, a text field fits well.
And so for such use-cases, Elasticsearch also allows you to assign multiple types to a field. Here’s how you do it in the Kibana console.
"brand": {
"type": "keyword",
"fields": {
"raw": {
"type": "text"
}
}
}
has_next_day_delivery
This is a boolean-type field that tells whether the product can be delivered within the next day.
Elasticsearch optimizes numeric fields, such as integer or float, for range queries.
retail_price
Kibana erroneously assigned this a keyword type, which I changed to float. This will be useful when a user wants to search for products within a certain price range.
product_rating
A number between 0 to 5, where 5 indicates the highest rating on average given by customers, and 1 being the lowest. 0 indicates that the product hasn’t been rated yet. I changed the type of this field to half_float.
Once you’ve imported your dataset, you can look at the mappings by going to the Index Management section in Kibana.
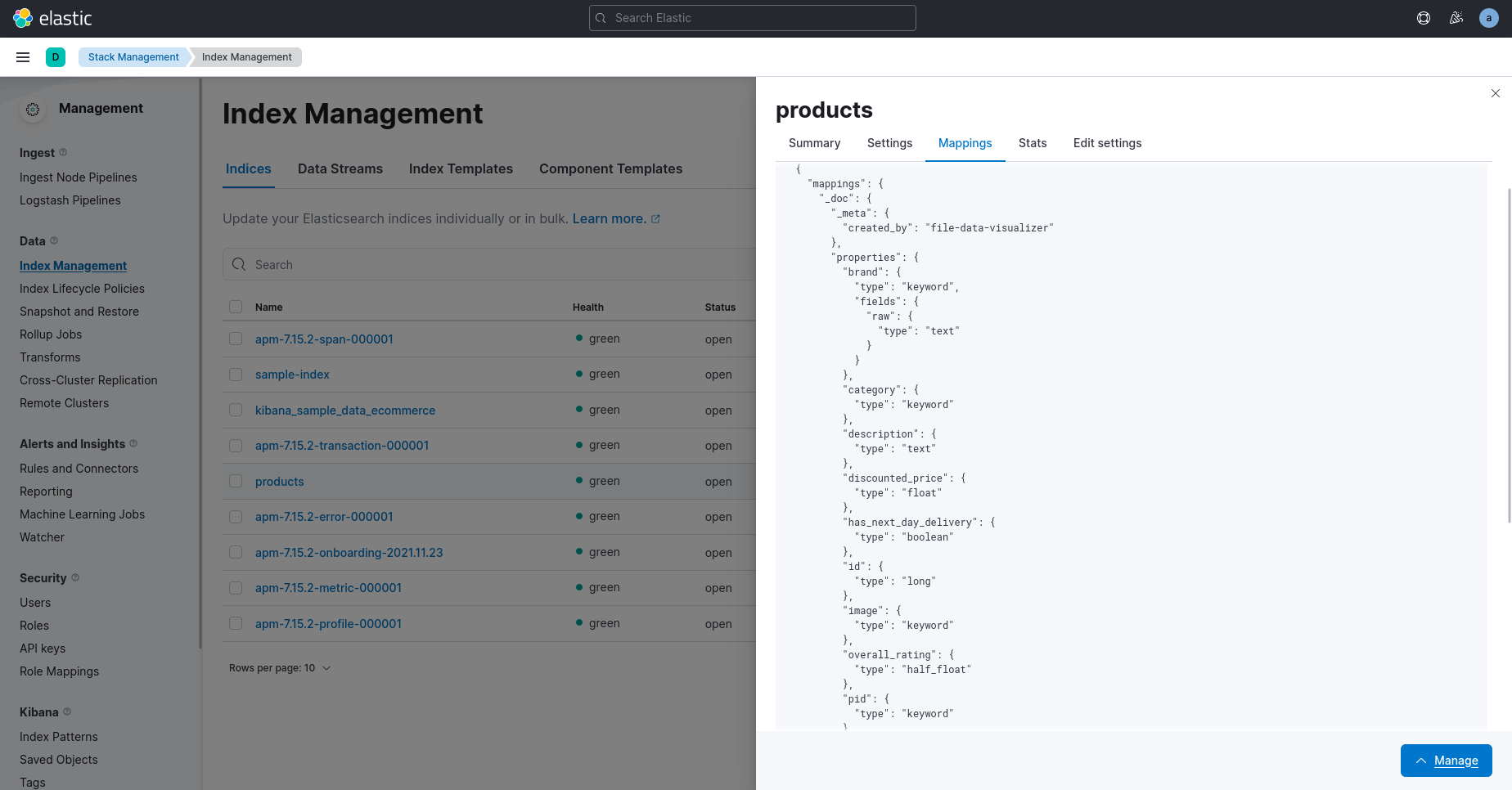
Here’s the JSON of the mappings:
{
"mappings": {
"_doc": {
"_meta": {
"created_by": "file-data-visualizer"
},
"properties": {
"brand": {
"type": "keyword",
"fields": {
"raw": {
"type": "text"
}
}
},
"category": {
"type": "keyword"
},
"description": {
"type": "text"
},
"discounted_price": {
"type": "float"
},
"has_next_day_delivery": {
"type": "boolean"
},
"id": {
"type": "long"
},
"image": {
"type": "keyword"
},
"overall_rating": {
"type": "half_float"
},
"pid": {
"type": "keyword"
},
"product_name": {
"type": "text"
},
"product_rating": {
"type": "half_float"
},
"product_url": {
"type": "keyword"
},
"retail_price": {
"type": "float"
},
"uniq_id": {
"type": "keyword"
}
}
}
}
}
Kibana Developer Console
The Kibana Devtools has a console that allows you to write and test different kinds of queries on your dataset.
Let’s try out one.
Get information about documents in an index
Type GET products/_search on the console, and hit the run icon on the right to execute the query. This tells Elasticsearch to fetch some sample documents from the products index.
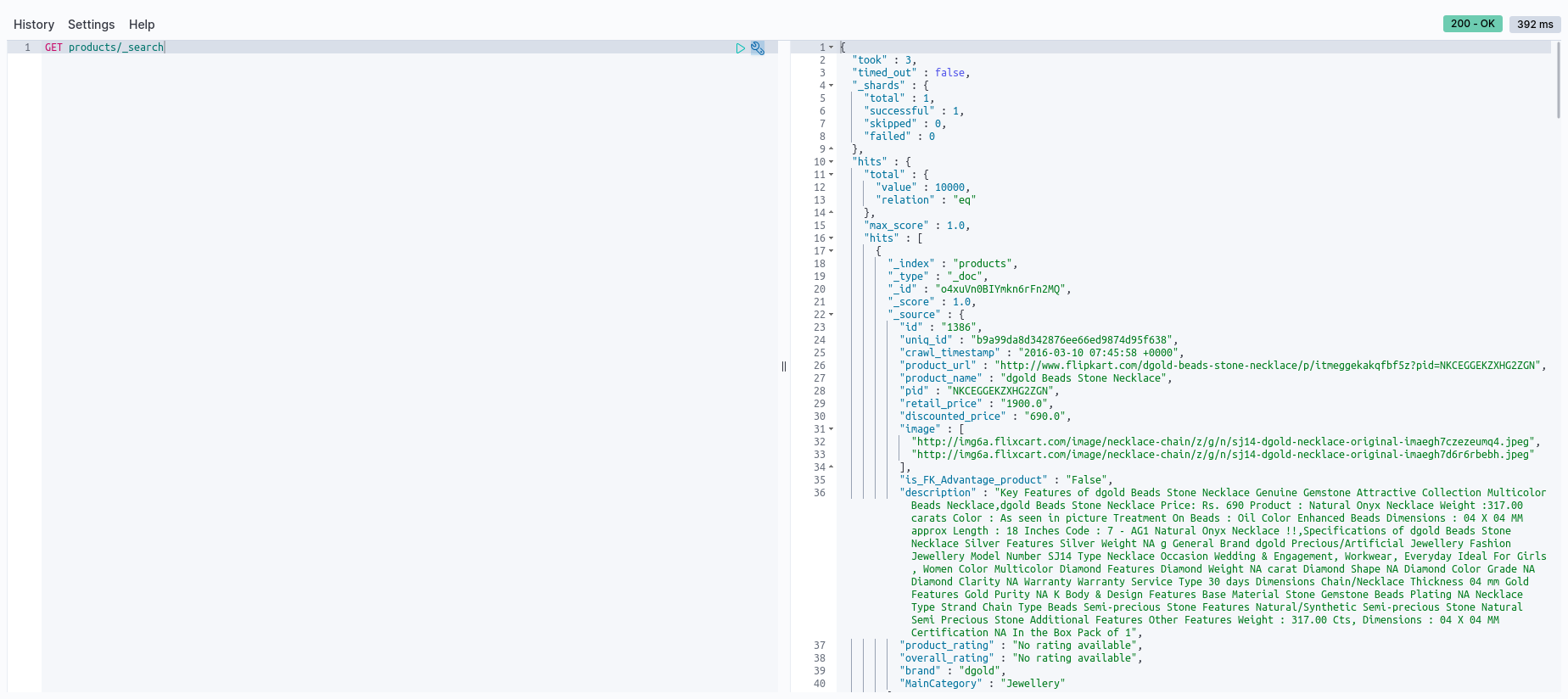
As you can see, Elasticsearch returns a JSON response with a sample list of documents from that index, along with plenty of useful metadata as well. Here’s a quick breakdown of what each of those fields mean:
hits contains some metadata along with the actual hits found in your dataset.
total: Indicates how many number of actual documents were identified as hits. By default, Elasticsearch returns 10000 in the response. So if your dataset contains more than 10000 documents, this field would still indicate 10000.relation: This indicates whether the actual number of hits are equal to, less than, or greater than the total hits returned in the response.
By default, this query returns an array of 10 hits. Within each hit, you’ll find some additional metadata:
_score: This is the value assigned by Elasticsearch’s ranking algorithm to determine how relevant the document is. Since this API returns only a sample, all documents contain the same value of 1._index: Indicates the field that the document was retrieved from.
This an example of a basic search query using Kibana. Let’s try another one.
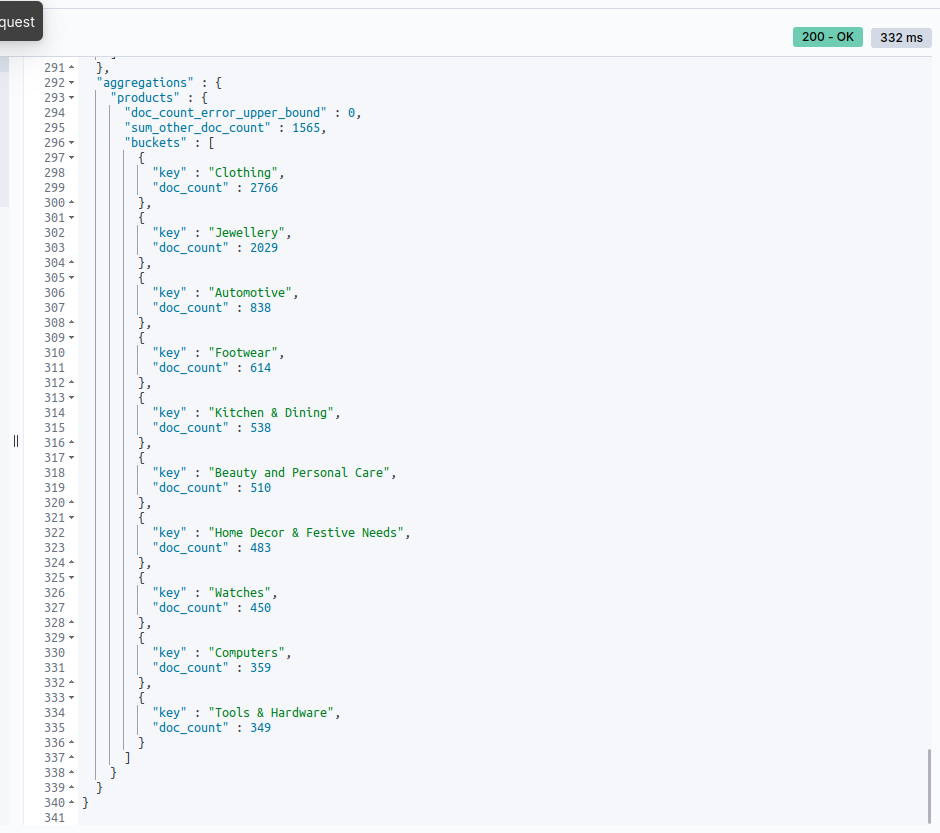
Find the number of products in each category
On the console, type this:
GET products/_search
{
"aggs": {
"products": {
"terms": {
"field": "category",
"size": 1000
}
}
}
}
It’ll return the following response
Common terminologies
If you’re just getting acquainted with search engines, you will frequently come across terms such as ranking and score. These terms are often inter-related to one another. It’s useful to understand what they mean and stand for before you begin to dive into querying in Elasticsearch.
Ranking
Ranking determines the order in which search results are returned, by assigning each hit a relevance score. Results are then ordered in decreasing order of their scores - with the highest scores at the top of the list, and the least scored items at the bottom of the list.
Score
Score is a value that implies how relevant the document is to the user. Higher the score, more relevant is the item, and vice-versa. A variety of factors are involved in determining the score of a document, such as:
Term frequency: How many times the search term, or a subset of the search term, appears in the document.
Inverse Term frequency: Often in the query, there might be words or phrases that occur too often in several documents, such as “How to”, or “the”. When such terms are encountered within a document, inverse term frequency lowers the weight for that document, and increases the weight for terms that occur rarely.
Searching for information
Elasticsearch exposes a set of REST APIs to allow users to query for information. A search query is given in the form of a GET request, after which Elasticsearch processes it and returns the results as a JSON response.
There are two main ways to search in Elasticsearch:
- Queries retrieve documents that match the specified criteria.
- Aggregations present the summary of your data as metrics, statistics, and other analytics.
Simple Text Queries
Query #1: Text search for a product
This is done using a match query. Here’s the syntax:
GET name-of-index/_search
{
"query": {
"match": {
"Column/field within which to search": {
"query": "Search keywords"
}
}
}
}
Here’s a query that searches for shoes in the product_name field and returns upto a 100 products:
GET products/_search
{
"size": 100,
"query": {
"match": {
"product_name": {
"query": "shoes"
}
}
}
}
Here’s the response
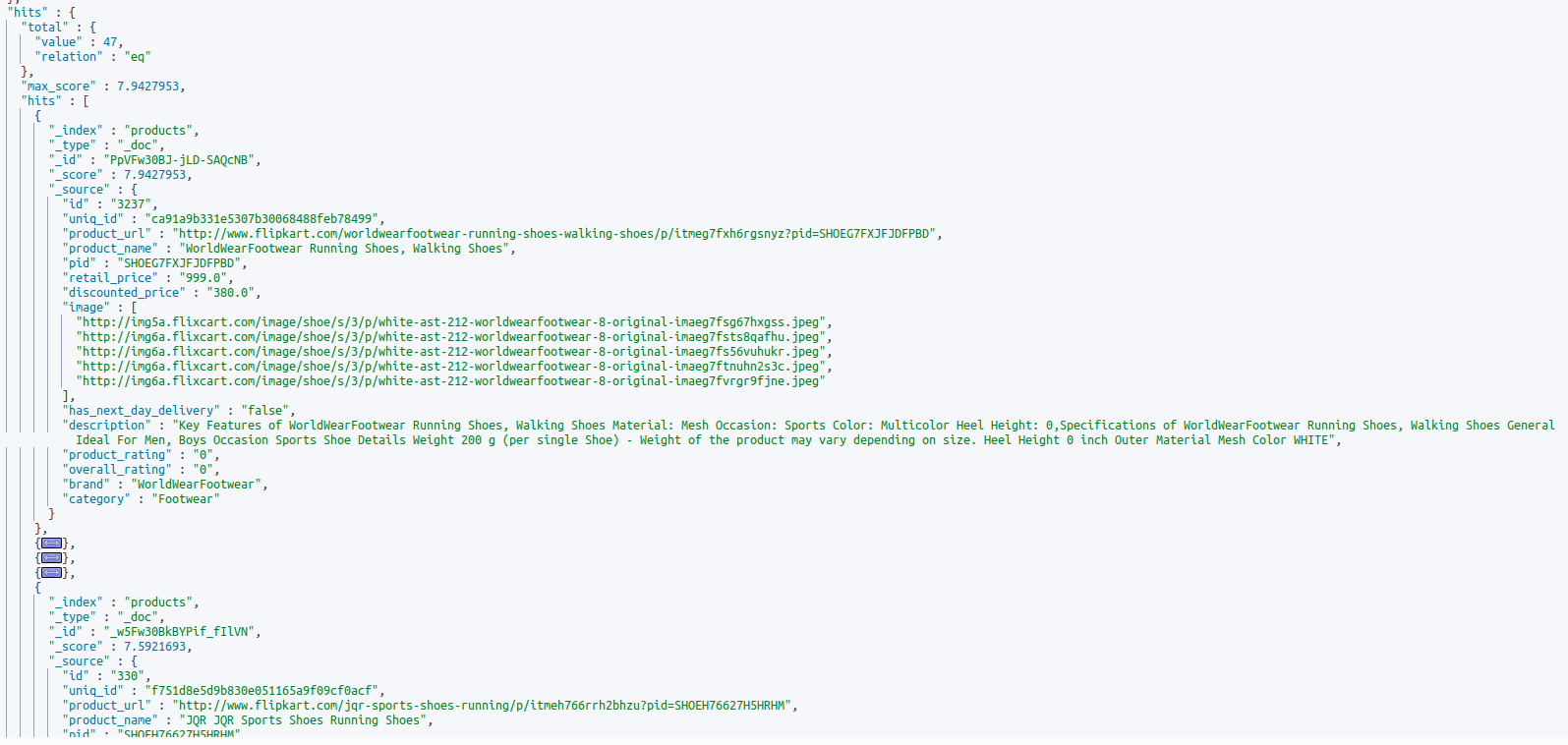
Here’s a sample structure of the JSON response:
"hits" : [
{
"_score" : 7.9427953,
"_source" : {
"product_name" : "WorldWearFootwear Running Shoes, Walking Shoes",
"pid" : "SHOEG7FXJFJDFPBD",
"retail_price" : "999.0",
"discounted_price" : "380.0",
"image" : [
"http://img5a.flixcart.com/image/shoe/s/3/p/white-ast-212-worldwearfootwear-8-original-imaeg7fsg67hxgss.jpeg",
],
"has_next_day_delivery" : "false",
"description" : "Key Features of WorldWearFootwear Running Shoes, Walking Shoes Material: Mesh Occasion: Sports Color: Multicolor Heel Height: 0,Specifications of WorldWearFootwear Running Shoes, Walking Shoes General Ideal For Men, Boys Occasion Sports Shoe Details Weight 200 g (per single Shoe) - Weight of the product may vary depending on size. Heel Height 0 inch Outer Material Mesh Color WHITE",
"product_rating" : "0",
"overall_rating" : "0",
"brand" : "WorldWearFootwear",
"category" : "Footwear"
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "xg5Fw30BkBYPif_fIlZO",
"_score" : 7.9427953,
"_source" : {
"id" : "529",
"uniq_id" : "b168c7b936c3ad9d9a02f1bfafa4926d",
"product_url" : "http://www.flipkart.com/steppings-running-shoes-casuals/p/itmebg6znr8nbwth?pid=SHOEBG6ZUGTSDGBU",
"product_name" : "Steppings Running Shoes Casuals Shoes",
"pid" : "SHOEBG6ZUGTSDGBU",
"retail_price" : "3699.0",
"discounted_price" : "2589.0",
"image" : [
"http://img6a.flixcart.com/image/shoe/k/t/6/black-8120-2-steppings-39-1000x1000-imaebg2fcsnjff8h.jpeg",
],
"has_next_day_delivery" : "false",
"description" : "Adidas Running Shoes Casuals Shoes. Price: Rs. 2,589. . Feel on the top of the world with this pair of Shoes by Adidas. Let the sun go down for uncomfortable sandals, opt for this pair of Flats that is crafted using a comfortable sole. Team this pair with a midi skirt and a floral crop top for an ultimate look..Feel on the top of the world with this pair of Shoes by Adidas. Let the sun go down for uncomfortable sandals, opt for this pair of Flats that is crafted using a comfortable sole. Team this pair with a midi skirt and a floral crop top for an ultimate look.",
"product_rating" : "0",
"overall_rating" : "0",
"brand" : "Adidas",
"category" : "Footwear"
}
},
But sometimes, the word shoes may not always appear in the product’s name. Often, sellers may name them sneakers or something in the name, but will put in the word shoes in the product’s description.
In such a case, you’ll need to search across multiple columns/fields. That’s where the multi-match query can help.
Here’s the syntax:
GET products/_search
{
"query": {
"multi_match": {
"query": "Search keywords",
"fields": ["field1", "field2"]
}
}
}
So here’s how you can retrieve products containing the word shoes in both the name and the description:
GET products/_search
{
"size": 100,
"query": {
"multi_match": {
"query": "shoes",
"fields": ["product_name", "description"]
}
}
}
Query #2: Text search for a product with a brand name or a certain phrase
Sometimes, a product name contains 2 or more words, in which case the order of the words that you type become important. Here are a few examples:
- Microsoft Surface
- United Colors of Benetton
When a search phrase containing 2 or more words need to appear in the same order, and they must appear next to each other, a Match phrase query is useful.
GET name-of-index/_search
{
"query": {
"match_phrase": {
"Column/field within which to search": {
"query": "Search phrase"
}
}
}
}
Here’s a query that searches for Kindle Paperwhite:
GET products/_search
{
"size": 100,
"query": {
"match_phrase": {
"product_name": {
"query": "Kindle Paperwhite"
}
}
}
}
But this need not be limited to just the product_name field. Here’s the syntax for searching for a phrase across multiple fields:
GET name-of-index/_search
{
"query": {
"multi_match": {
"query": "Search phrase",
"fields": [
"field_1",
"field_2",
"field_3"
],
"type": "phrase"
}
}
}
Here’s an example:
GET products/_search
{
"query": {
"multi_match": {
"query": "Kindle Paperwhite",
"fields": [
"product_name",
"description",
],
"type": "phrase"
}
}
}
Query #3: Search for a particular category of products
Often, shoppers will click on a particular category on the home page to search for products and browse through them, as opposed to typing a particular search phrase. This can be done using a term query. Here’s the syntax:
GET name-of-index/_search
{
"query": {
"term": {
"name-of-field": "keyword",
}
}
}
In our dataset, the category field is of the keyword type, which makes it possible for us to use a term query.
So in the above picture, when a user clicks on the Grocery category, the following query can be used to fetch and display grocery items:
GET products/_search
{
"query": {
"term" : { "category" : "Grocery" }
}
}
Compound Queries
Compound queries allow you to combine 2 or more queries into more sophisticated ones. For example:
- Use a text search to look up products, but only within a certain category or categories.
- Look up a product within a certain price range, or above a certain rating.
- Or all of the above!
For this, a bool query comes in handy. It allows you to combine multiple queries into a single one wih the help of boolean clauses:
must: All queries in the must clause must be satisfied for a document to be returned as a hit.should: Theshouldallows you to specify nice-to-haves. In other words, it will still return documents that don’t match those nice-to-have or desirable conditions, but if they do, they will be ranked above than the ones that don’t match.must_not: You can tell elasticsearch to not include certain products if they match some conditions.filter: This behaves exactly like themustquery, except that the score of the matching documents isn’t computed. When the score doesn’t matter and all you care about is whether documents match the filter criteria, it is recommended to use this query. Elasticsearch automatically caches frequently used filter queries to give them a performance boost.
Let’s look at how we can use compound queries to map out a user’s search journey.
Here’s a user searching for the smartphone “Redmi Note 10” in the Smartphones category on Amazon:
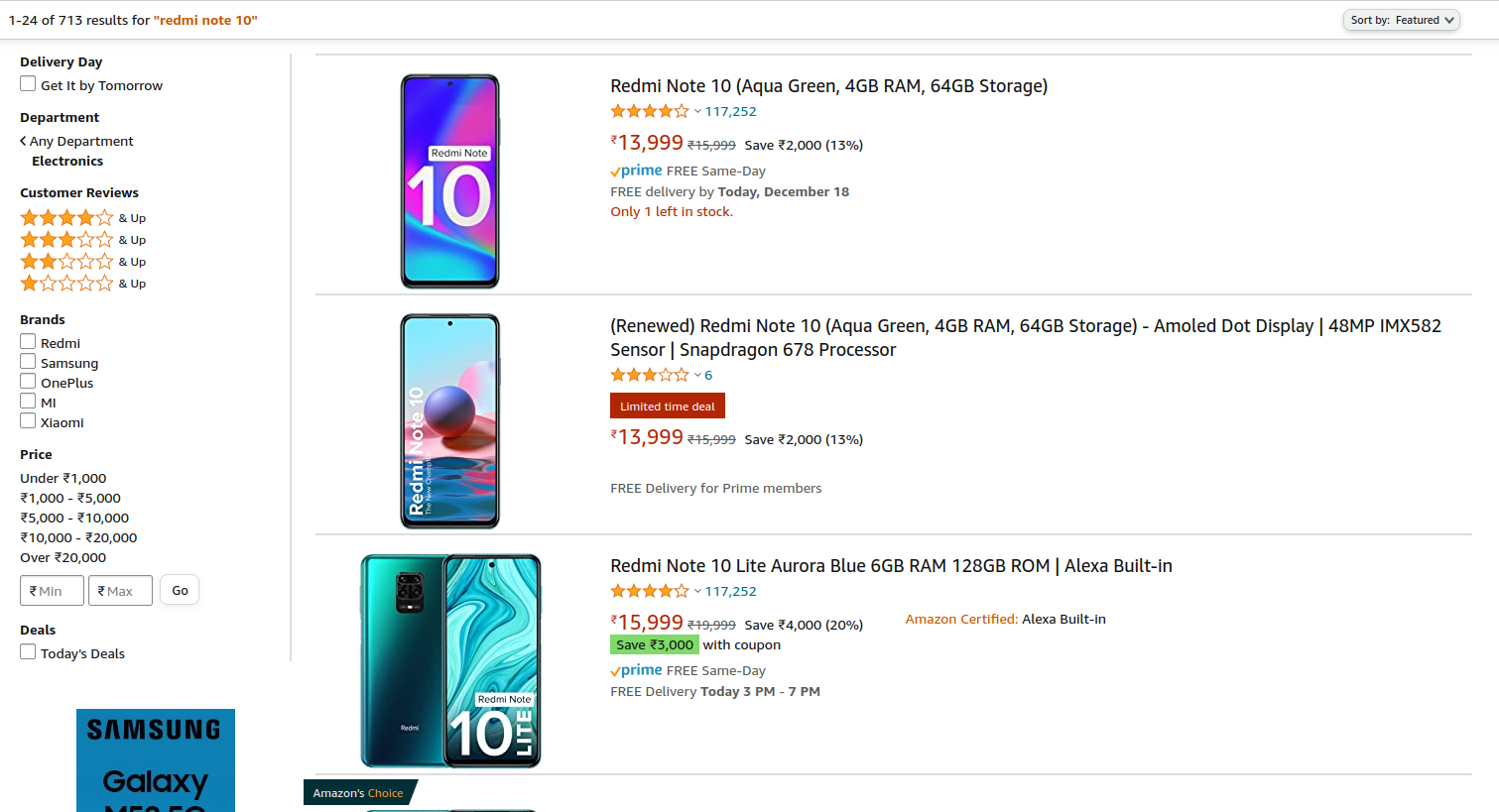
Query #4: Text search for products within a certain category
In-order to make search results relevant, shoppers often search for products within a certain department.
As an example, the following query can be used to search for “Redmi Note 10” in the “Smartphones” category:
GET products/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"product_name": "Redmi Note 10"
}
},
{
"term": {
"category": "Smartphones"
}
}
]
}
}
}
Here’s the general syntax:
GET name-of-index/_search
{
"query": {
"bool": {
"must": [
{
"match/match_phrase/term": {
"name-of-field": "value"
}
},
{
"match/match_phrase/term": {
"name-of-field": "value"
}
}
]
}
}
}
Query #5: Search and filter for products by ratings
For this, we can use the range query. Here’s the general syntax:
GET name-of-index/_search
{
"query": {
"bool": {
"must": [
{
"match/match_phrase/term": {
"name": "Enter the value you are looking for"
}
},
{
"range":{
"field-name": {
"gte": "Enter lowest value of the range here",
"lte": "Enter highest value of the range here"
}
}
}
]
}
}
}
Here’s how we apply it:
GET products/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"product_name": "Redmi Note 10"
}
},
{
"term": {
"category": "Smartphones"
}
},
{
"range":{
"product_rating": {
"gte": "4",
}
}
}
]
}
}
}
Query #6: Filter by pricing parameters
Similarly, applying a price range works the same way:
GET products/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"product_name": "Redmi Note 10"
}
},
{
"term": {
"category": "Smartphones"
}
},
{
"range": {
"product_rating": {
"gte": "4",
}
}
},
{
"range": {
"retail_price": {
"gte": 300,
"lte": 450
}
}
}
]
}
}
}
Sorting search results
By default, Elasticsearch returns a list of documents sorted by most relevant to least relevant. In online shopping however, shoppers like to view search results sorted by pricing, or customer ratings as well.
Here’s the general syntax:
GET name-of-index/_search
{
"sort" : [
{
"field-name": {
"order": "specify-a-sort-order"
}
}
],
"query": {
...
}
}
Here’s how we can apply it in the previous query:
GET products/_search
{
"sort" : [
{
"retail_price": {
"order": "asc"
}
}
],
"query": {
"bool": {
"must": [
{
"match_phrase": {
"product_name": "Redmi Note 10"
}
},
{
"term": {
"category": "Smartphones"
}
},
{
"range": {
"product_rating": {
"gte": "4",
}
}
},
{
"range": {
"retail_price": {
"gte": 300,
"lte": 450
}
}
}
]
}
}
}
Improving search relevance
When you search for something, you want to see the most relevant search results on the top. It can be frustrating when the search results are not exactly what you were looking for.
Search engines like the one that you see on Google’s home page determine the relevance of your query using a variety of criteria - such as the text input, geolocation, accuracy of your spelling, and even the intent by analyzing your browsing patterns using machine learning techniques. In-fact, they can be so sophisticated that they fall in a category of their own - recommendation engines.
Search relevance is the measure of accuracy of the relationship between the search query and the search results. Which raises the question -
How do we measure the relevance of the results returned from a search query?
To understand this better, let’s look at the characteristics of the data that may or may not be returned by the search engine.

In the above diagram, the dots represent the entire dataset stored in our database. When we search for something using a search engine, the dots within the circle indicate the document that is selected by the search engine as being relevant, also called hits. A ranking algorithm assigns each of these hits a score, after which they are returned back to the user.
True positives: These are data that are truly relevant to the user, and are also identified by the search engine as relevant and returned to the user as the response.
False positives: These are data that are not relevant to the search query, but are still marked by the search engine as being relevant and returned back.
True negatives: These are documents that are not relevant, and are correctly omitted by the search engine amongst the returned results.
False negatives: These are documents that are in-fact relevant to the search query, but were not identified by the search engine. Therefore they were not returned back in the search results, when they should have been returned.
Broadly speaking, there are two factors - precision and recall - that are used to measure the relevancy of search results.
Precision
Precision consists of the dots within the circle in the above diagram. It tells us what proportion of results that were identified as relevant by the search engine truly are relevant. It is a ratio of true positives (documents identified as relevant, and which are actually relevant) to all positives (all documents identified as relevant, irrespective of whether that was correct). In other words, it is the ratio of True Positives/(True Positives + False Positives).
Recall
Recall or sensitivity, is another metric that’s about the dots within the left part of the above diagram. It tells us what proportion of documents that actually are relevant to our search query, were identified by the search engine as being relevant. It is a ratio of true positives (documents identified by the search engine as relevant, and which are actually relevant) to all the data that are relevant (irrespective of whether the search engine identified them correctly). The formula for this metric is given by - True Positives/(True Positives + False Negatives).
Precision helps you understand what portion of data returned, are actually relevant. Whereas on the other hand, recall helps you understand what portion of relevant data are actually being returned. Together, these two factors determine the relevancy and quality of your search results.
In Elasticsearch, you can fine-tune your queries to be more precise, or have more recall. Since these two metrics are at odds with each other, fine-tuning for precision would make the search engine err on the side of returning less documents and focus more on quality, whereas whereas fine-tuning for relevance would make it focus more on quantity.
Let’s look at how we can improve the relevance of our search:
Boost the relevance of individual fields
If a search term occurs in specific fields of a document, you can tell Elasticsearch to boost their relevance score higher. Let’s see how this can be used within the context of grocery shopping.
I’m in the mood to have some strawberries. Let’s see if I can find any fresh ones on Walmart! 😋
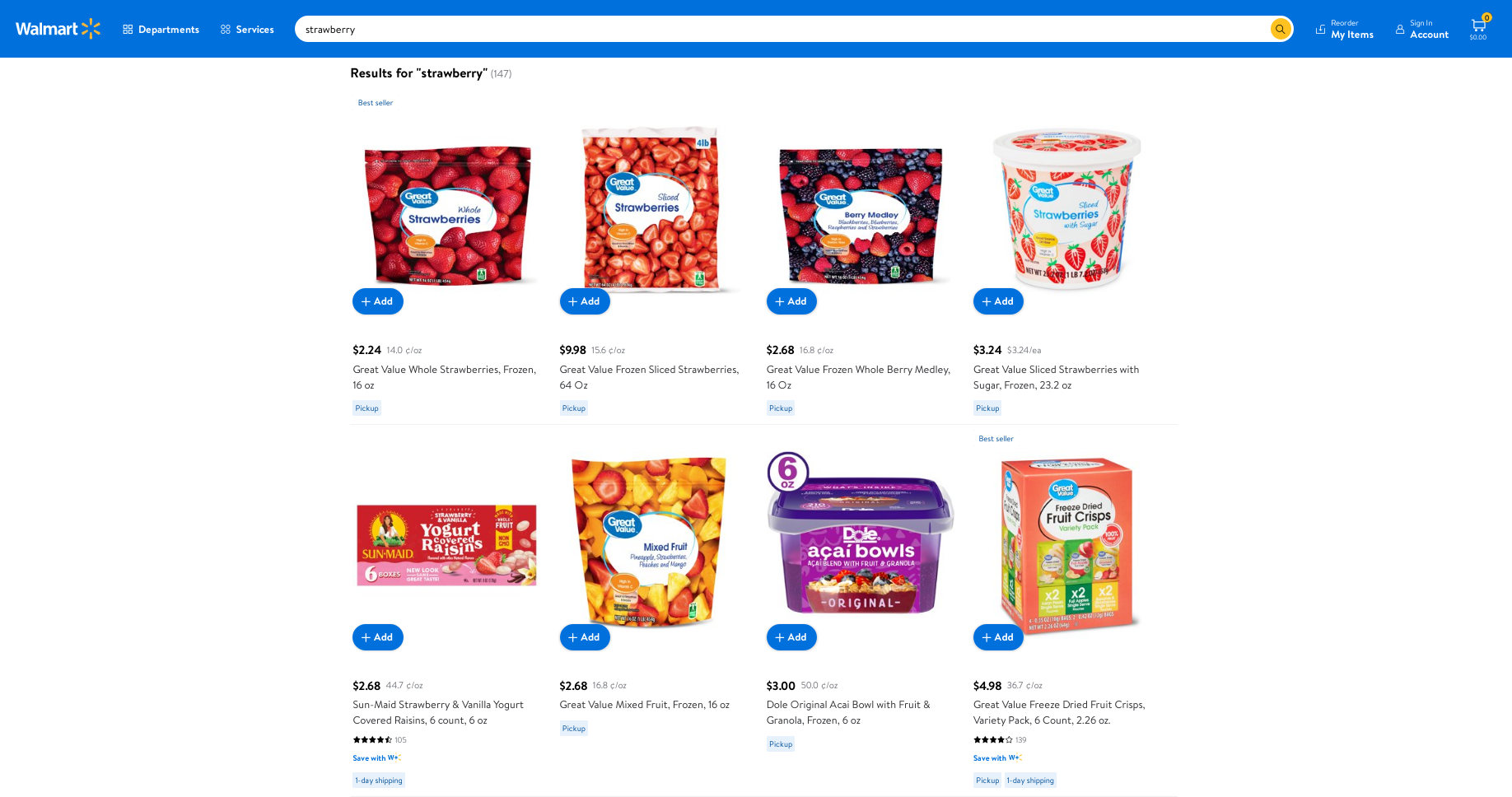
Notice how the search results show the actual fruits at the top, and shows products like mixed fruits, dried fruit etc towards the bottom?
When I click on the product titled Mixed fruit, here’s what the description reads:
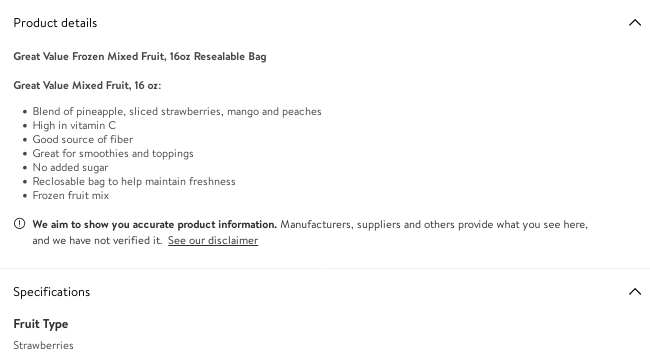
It seems like when you search for something like strawberries on Walmart, it searches across both the product name as well as the description fields. But its also clever enough to rank the products that contain the word strawberries in their titles higher, than the ones that have this word in their descriptions.
Why? Because products mentioning the word “strawberries” in their titles are more likely to be related to my search, than the products that mention “strawberries” in their description.
Elasticsearch allows you to boost individual fields in-order to improve the precision of your search results. So if we were to apply boosting on our dataset, here’s what it would look like:
GET products/_search
{
"query": {
"multi_match": {
"query": "strawberries",
"fields": [
"product_name^2",
"description",
]
}
}
}
This basically tells Elasticsearch to increase the weight of the product_name by a factor of 2. Here’s the general syntax:
GET name-of-index/_search
{
"query" : {
"multi_match": {
"query": "search term",
"fields": [
"field1^2",
"field2",
"field3"
]
}
}
}
Decrease the relevance of documents for certain search terms
There might be instances when you’d like to decrease the relevance of certain documents if they contain some search terms, without excluding them from the search results. Here’s an example:
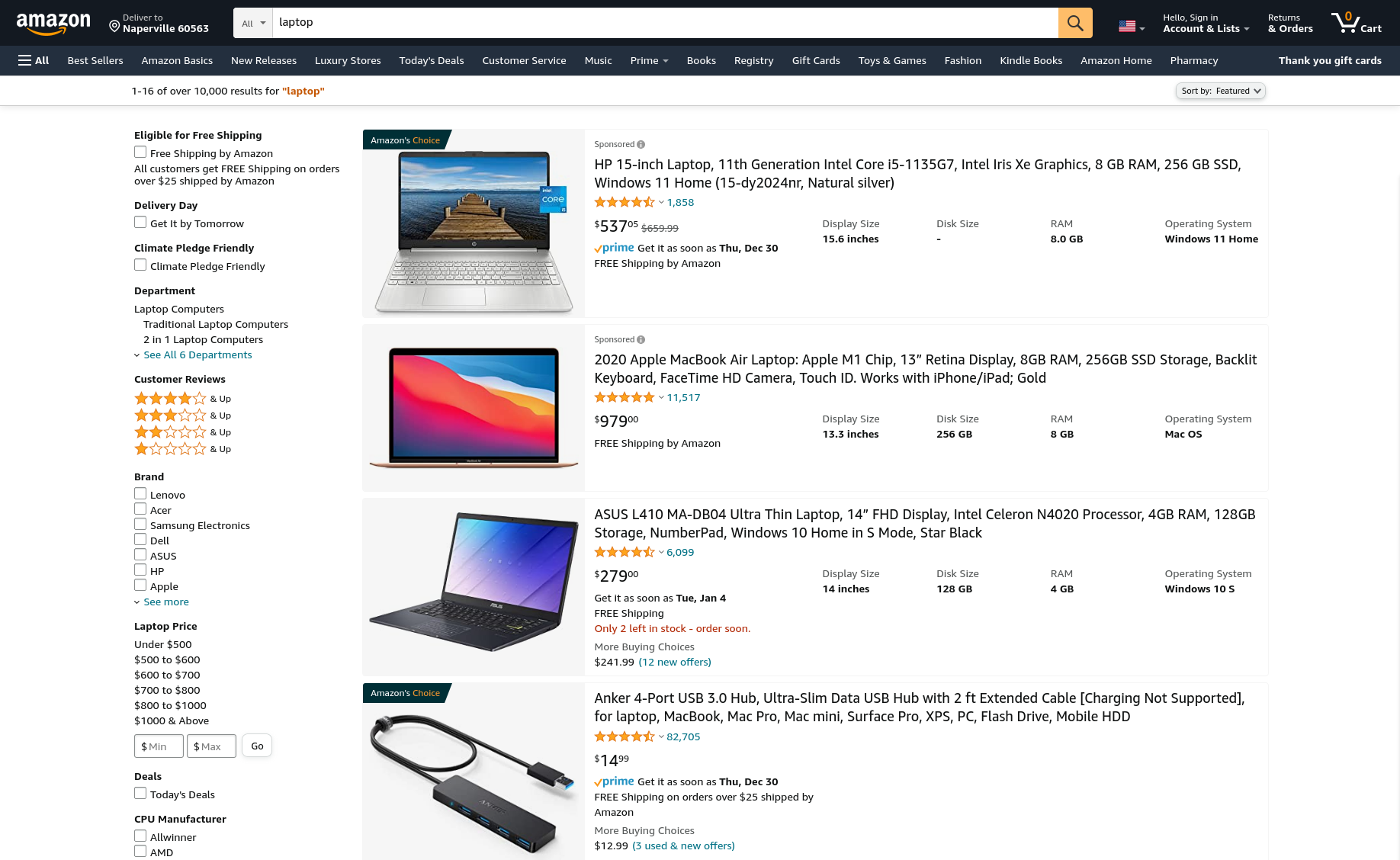
The top three products are indeed laptops, but the 4th one isn’t. Notice how the search lowered the relevance of a related product that contains the word laptop, but isn’t actually one? But Amazon very aptly thinks that this is something that I might be interested to buy, so it didn’t exclude it from the search results!
Elasticsearch allows you to apply negative boosting to demote certain documents without excluding them from the search results, with the help of the boosting query. Here’s how its done:
GET products/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"text": "laptop"
}
},
"negative": {
"term": {
"text": "usb"
}
},
"negative_boost": 2
}
}
}
Here’s the general syntax:
GET name-of-index/_search
{
"query" : {
"boosting": {
"positive": {
"term": {
"text": "search term"
}
},
"negative": {
"term": {
"text": "term to demote"
}
},
"negative_boost": 2
}
}
}
Tip
Use the should clause if you want to boost documents that contain certain additional terms.
Enhancing e-shopping experience even further
Most shoppers prefer using mobile devices. But typing on the search box isn’t nearly so easy as it is on a desktop! It take a lot more effort, and you’re more prone to making typos. A study from Grammarly shows that mobile users are nearly 5 times more likely to make mistakes while typing on a phone than on a regular PC!
Here are some cool features of Elasticsearch that you can leverage to further improve search on mobile:
- Suggesters: This adds an autocomplete suggestion feature, providing relevant search results as the user keeps typing on their search box!
- Fuzzy queries: Useful for handling typos and to provide “Did you mean this instead” feature. Guessing what the user actually intended to search for rather than returning no results at all is a great way to further enhance the shopping experience.
Summing up
If you have a retail platform, providing a means to search for products quickly and easily can immensely enhance the shopping experience for your users. This translates to more frequent purchases, better customer reviews and increased profits.
At Egen, we use Elasticsearch along with several other technologies to create captivating customer experiences for our retail customers. Here’s a sneak peak into the life of an Elasticsearch Architect in our organization:
Looking to create an amazing user experience for your retail application? Or have any questions related to this post? Say hello at digital@egen.solutions 👋
Resources
- The story of search
- Elasticsearch for beginners SQL developers
- Elasticsearch, bottoms-up - Videos
- Beginner’s Crash Course to Elastic Stack - Video Series
- Beginner’s Crash Course to Elastic Stack - Github documentation
- Indexing in Elasticsearch
Originally published in Egen Engineering